コードを表示
print(f"✅ トレーニングデータ: {len(training_data)}件")
print(f"✅ ユーザー文脈: {dataset['metadata']['user_context']}")✅ トレーニングデータ: 20件
✅ ユーザー文脈: メディア・エンターテインメント業界でAIを活用したコンテンツ制作業界ニュースを自動収集し、ユーザーのビジネス文脈に基づいて影響度を分析するメール配信サービスです。
配信内容の例:
しかし、このメール生成には以下の課題があります:
| 課題 | 具体例 | ビジネスインパクト |
|---|---|---|
| A: 根拠のない追加情報 | 本文にない「500社が採用」などを断定 | 誤情報による意思決定ミス |
| B: こじつけ・熱量ズレ | 無関係なニュースを「大きな影響」と過大評価 | 重要な情報が埋もれる |
| C: アクションが抽象的 | 「情報収集する」のみで5W1Hがない | 実行不可能なアクション |
本記事の目的: DSPyを用いて、これらの課題を定量的に改善します。
DSPy最適化のために、20サンプルのトレーニングデータを用意しました。
print(f"✅ トレーニングデータ: {len(training_data)}件")
print(f"✅ ユーザー文脈: {dataset['metadata']['user_context']}")✅ トレーニングデータ: 20件
✅ ユーザー文脈: メディア・エンターテインメント業界でAIを活用したコンテンツ制作# サンプル1の表示
sample = training_data[0]
print("=" * 80)
print(f"■ タイトル: {sample['input']['title'][:60]}...")
print(f"■ 期待スコア: {sample['expected_output']['impact_score']}/5")
print(f"\n■ 期待される要約:")
print(sample['expected_output']['article_summary'][:150] + "...")
print(f"\n■ 期待される短期アクション:")
print(sample['expected_output']['short_term_action'][:150] + "...")================================================================================
■ タイトル: Google、Gemini Nanoのコンテキストウィンドウを100万トークンに拡大...
■ 期待スコア: 5/5
■ 期待される要約:
GoogleがGemini Nanoのコンテキストウィンドウを100万トークンに拡大。長編脚本や小説全体を一度に処理可能になり、エッジデバイスでプライバシー重視のコンテンツ生成が実現できる。...
■ 期待される短期アクション:
HuggingFaceで公開されているGemini Nanoモデルにアクセスし、簡単なテキスト生成タスクで性能や使い勝手を具体的に把握する(30分〜半日)...このセクションでは、上記の本番プロンプトをDSPyで最適化し、実際にLLMに送られたプロンプトの変化を確認します。
ここからが本記事の主要部分です。実際にDSPyコードを実装し、プロンプト最適化の効果を検証します。
✅ DSPyセットアップ完了:
- LM: OpenAI GPT-5.2
- Optimizer: BootstrapFewShot
- トレーニングデータ: 20サンプル# Writer署名: 入力→出力の型を定義
class WriterSignature(dspy.Signature):
"""ニュース記事からユーザー文脈に基づいた影響度分析を生成する"""
title: str = dspy.InputField(desc="ニュース記事のタイトル")
news_content: str = dspy.InputField(desc="ニュース記事の本文")
user_context: str = dspy.InputField(desc="ユーザーの業界・職種")
impact_score: int = dspy.OutputField(desc="影響度スコア(1-5)")
article_summary: str = dspy.OutputField(desc="150文字前後の要約")
positive_impact: str = dspy.OutputField(desc="ポジティブな影響の説明")
negative_impact: str = dspy.OutputField(desc="ネガティブな影響の説明")
short_term_action: str = dspy.OutputField(desc="短期アクション(5W1H明記)")
# Writerモジュール: ChainOfThoughtで推論プロセスを含む
class Writer(dspy.Module):
def __init__(self):
super().__init__()
self.generate = dspy.ChainOfThought(WriterSignature)
def forward(self, title, news_content, user_context):
return self.generate(
title=title,
news_content=news_content,
user_context=user_context
)
print("✅ Writerモジュール定義完了")✅ Writerモジュール定義完了課題別評価Judgeの定義
# A: 根拠のない追加情報 (Faithfulness)
class FaithfulnessJudge(dspy.Signature):
"""出力(要約)が入力ニュース記事に基づいているか、幻覚がないかを判定"""
source_text: str = dspy.InputField(desc="元のニュース記事本文")
generated_text: str = dspy.InputField(desc="生成された要約")
claims: list[str] = dspy.OutputField(desc="生成文から抽出した主要な主張リスト")
unsupported_claims: list[str] = dspy.OutputField(desc="ソースに基づく根拠が見当たらない主張")
score: float = dspy.OutputField(desc="0.0-1.0のスコア。1.0=全て根拠あり")
# B: こじつけ・熱量ズレ (Relevance Calibration)
class RelevanceJudge(dspy.Signature):
"""ニュースとユーザー文脈の関連性を評価し、Writerがつけたスコアが妥当か判定"""
news_content: str = dspy.InputField(desc="ニュース記事")
user_context: str = dspy.InputField(desc="ユーザーの業界・職種")
stated_score: int = dspy.InputField(desc="Writerがつけた影響度スコア(1-5)")
actual_score: int = dspy.OutputField(desc="客観的に見た適正スコア(1-5)")
reasoning: str = dspy.OutputField(desc="適正スコアの理由")
# C: アクションが抽象的 (Action Specificity)
class ActionSpecificityJudge(dspy.Signature):
"""アクションアイテムが具体的(5W1H)で実行可能かを評価"""
action_item: str = dspy.InputField(desc="提案されたアクション")
has_what: bool = dspy.OutputField(desc="何をするか明確か")
has_who: bool = dspy.OutputField(desc="誰がやるか明確か (自分/チーム等)")
has_when: bool = dspy.OutputField(desc="期限やタイミングが明確か")
has_how: bool = dspy.OutputField(desc="具体的な手段・ツールが明確か")
is_actionable: bool = dspy.OutputField(desc="明日から即実行できる具体性があるか")
# モジュールのインスタンス化
faithfulness_judge = dspy.ChainOfThought(FaithfulnessJudge)
relevance_judge = dspy.ChainOfThought(RelevanceJudge)
action_judge = dspy.ChainOfThought(ActionSpecificityJudge)
print("✅ Judgeエージェント(Faithfulness, Relevance, Action)定義完了")
# --- 統合メトリクス ---
def combined_email_quality_metric(example, prediction, trace=None):
"""3つの課題を統合した品質スコア (LLM-as-a-Judge)"""
# 1. Faithfulness Metric (課題A)
# 要約が事実に即しているか
try:
f_result = faithfulness_judge(
source_text=example.news_content,
generated_text=prediction.article_summary
)
faithfulness_score = f_result.score
except:
faithfulness_score = 0.0
# 2. Relevance Calibration Metric (課題B)
# スコアのズレに対するペナルティ
try:
r_result = relevance_judge(
news_content=example.news_content,
user_context=example.user_context,
stated_score=int(prediction.impact_score)
)
actual = r_result.actual_score
stated = int(prediction.impact_score)
# ズレに応じて減点 (過大評価をより重く罰する例など調整可能)
diff = abs(actual - stated)
if diff == 0:
relevance_score = 1.0
elif diff == 1:
relevance_score = 0.5
else:
relevance_score = 0.0
except:
relevance_score = 0.0
# 3. Action Specificity Metric (課題C)
# 5W1Hの網羅度
try:
a_result = action_judge(action_item=prediction.short_term_action)
components = [
a_result.has_what,
a_result.has_who,
a_result.has_when,
a_result.has_how,
a_result.is_actionable
]
specificity_score = sum(components) / len(components)
except:
specificity_score = 0.0
# 統合スコア (重み付け)
# 誤情報(Faithfulness)は許容できないため高めの重み
weights = {
"faithfulness": 0.4,
"relevance": 0.3,
"specificity": 0.3
}
combined = (
faithfulness_score * weights["faithfulness"] +
relevance_score * weights["relevance"] +
specificity_score * weights["specificity"]
)
# デバッグ用出力 (MIPROのログで確認可能)
if trace is not None:
pass # DSPyの内部トレース用
return combined
print("✅ 統合評価メトリクス (LLM Judge) 定義完了")
### Writer実行: 最適化前
# デモ用のサンプルを選択
demo_sample = training_data[0]
# 最適化前のWriterを実行
writer_baseline = Writer()
result_baseline = writer_baseline(
title=demo_sample['input']['title'],
news_content=demo_sample['input']['news_content'],
user_context=demo_sample['input']['user_context']
)
# 最適化前のプロンプトを保存
# inspect_history()の代わりに、lm.historyを直接取得
try:
if hasattr(lm, 'history') and lm.history:
# 最新のメッセージを取得
last_prompt_before = str(lm.history[-1])
else:
last_prompt_before = None
except Exception as e:
last_prompt_before = None
print(f"警告: プロンプト履歴の取得に失敗しました: {e}")✅ Judgeエージェント(Faithfulness, Relevance, Action)定義完了
✅ 統合評価メトリクス (LLM Judge) 定義完了print("✅ 最適化前のWriter実行完了")
print(f"影響度スコア: {result_baseline.impact_score}")
print(f"要約: {result_baseline.article_summary[:100]}...")✅ 最適化前のWriter実行完了
影響度スコア: 5
要約: GoogleがGemini Nanoのコンテキストを100万トークンに拡大。脚本や小説を一度に処理でき、Hugging Faceで公開。エッジ動作にも対応し、外部送信を抑えたプライバシー重視の生成が可...従来の手動でのプロンプト試行錯誤(Prompt Engineering)から、プログラムとしてプロンプトを最適化する(Prompt Programming)アプローチへ移行します。
参照: From Prompt Tuning to Prompt Programming
MIPRO (Multi-Prompt Instruction Proposal Optimizer) は、この「Prompt Programming」を具現化するDSPyのオプティマイザーです。
アプローチの違い: - Prompt Engineering: 人間が指示を手動で書き換える - Prompt Programming (MIPRO): 1. データから最適な「指示(Instruction)」を自動生成・提案 2. 最適な「数ショット例(Few-shot)」を自動選択 3. これらを組み合わせ、スコアが最大になるものを探索
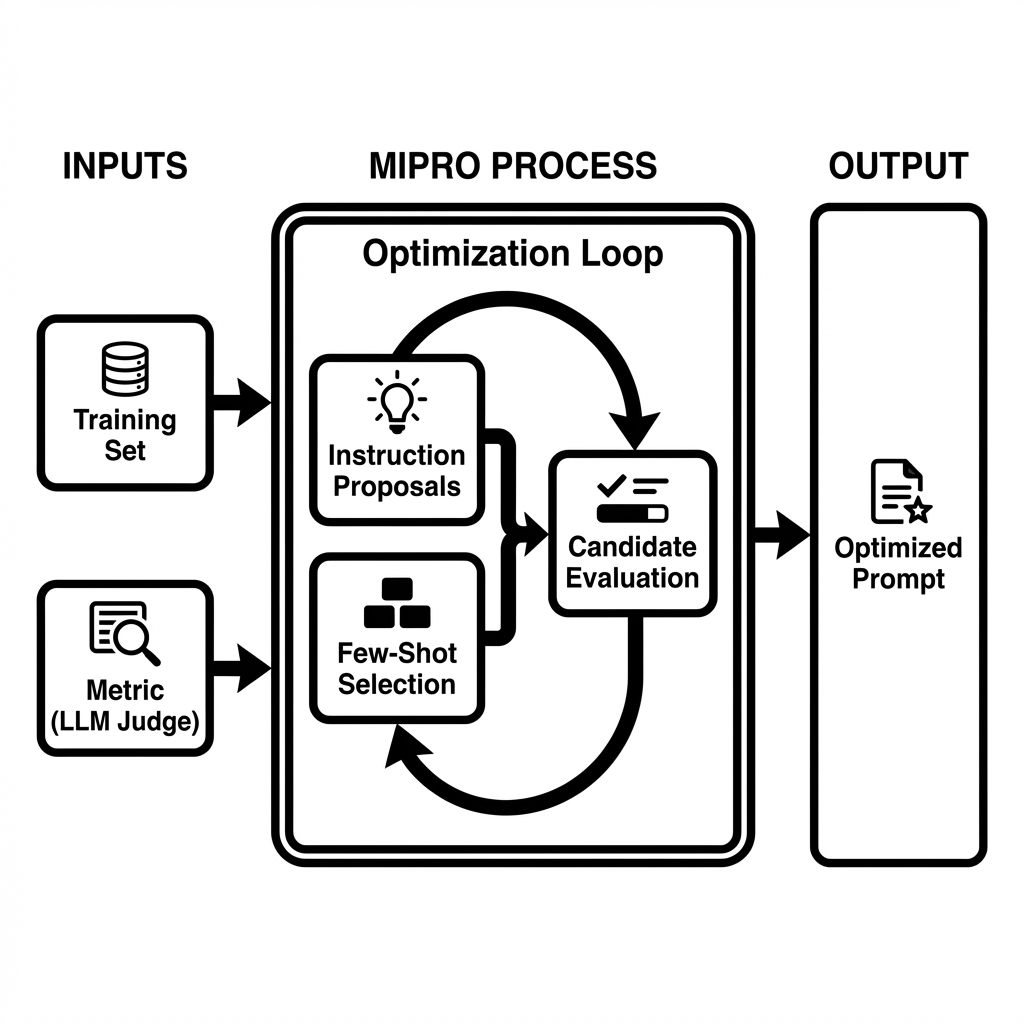
MIPROは、単に例を追加するだけでなく、タスクの定義そのもの(Signatureの命令文) を書き換えます。
from dspy.teleprompt import MIPROv2
# MIPROで最適化(指示文 + Few-shot例)
print("\n🔄 MIPRO最適化を実行中...")
print(" - Prompt Programmingアプローチ: データから最適な指示と例を探索")
print(" - auto='light'モードで高速に最適解を探索")
# データセットを最大活用(全20件)
full_trainset = []
for sample in training_data:
ex = dspy.Example(
title=sample['input']['title'],
news_content=sample['input']['news_content'],
user_context=sample['input']['user_context'],
impact_score=str(sample['expected_output']['impact_score']), # 文字列として扱う
article_summary=sample['expected_output']['article_summary'],
short_term_action=sample['expected_output']['short_term_action']
).with_inputs('title', 'news_content', 'user_context')
full_trainset.append(ex)
# オプティマイザーの設定
# metricに先ほど定義した統合LLM-Judgeメトリクスを指定
mipro_optimizer = dspy.MIPROv2(
metric=combined_email_quality_metric,
auto=None,
num_candidates=3, # 候補数を減らして高速化 (実験用)
init_temperature=1.0,
max_bootstrapped_demos=3,
max_labeled_demos=4,
num_threads=1,
verbose=False
)
# コンパイル実行(最適化)
# trainsetとvalsetを分けて使用
# 実験のためデータ数を絞って高速化: train=5件, val=5件
mipro_optimized_writer = mipro_optimizer.compile(
Writer(),
trainset=full_trainset[5:10], # 5件のみ使用 (実験用)
valset=full_trainset[:5],
num_trials=3, # 試行回数を3回に減らして高速化 (実験用)
minibatch=False,
)
print("✅ MIPRO最適化完了: 最適なPrompt Programが生成されました")💡 実行時間: MIPROは複数のプロンプト候補を生成・評価するため、15分程度かかります。
実際に最適化されたプログラムを実行し、どのようなプロンプトが生成されたかを確認します。
影響度スコア: 4
要約: GoogleはGemini Nanoのコンテキストウィンドウを100万トークンに拡大したと発表。長編脚本や小説全体を一度に処理可能。モデルはHugging Faceで公開され、開発者が利用でき、エッジ...MIPROによって、システムプロンプト(指示文)がどのように書き換わったかを確認します。
MIPROは、与えられた教師データとスコアリングロジック(LLM Judge)から逆算して、以下のような「勝ちパターン」を言語化しました。
| 特徴 | Before (人間が作成) | After (MIPROが生成) |
|---|---|---|
| 役割設定 | 「経営・戦略コンサルタント」 → 一般的で広い |
「業務向けの意思決定支援アナリスト」 → 判断と事実にフォーカス |
| 指示の具体性 | 「詳細に評価してください」 → LLM任せ |
「調査→検証→適用判断に沿った実務単位の示唆」 → 思考プロセスまで指定 |
| 幻覚対策 | 特になし | 「記事に書かれていない事実は推測で断定しないこと」 → 明確な禁止事項 |
| 出力要件 | 項目名の羅列のみ | 「5W1H明記」「所要時間を入れる」「PoC手順を含める」 → 具体的な記載事項を指定 |
| 文脈の反映 | 変数として渡すのみ | プロンプト内に「メディア・エンタメ業界でAIを活用…」と直接埋め込み |
このように、MIPROは「良い出力」を得るために必要な指示の解像度を、人間よりも遥かに細かく、かつ正確に調整していることがわかります。
# 課題が発生しやすい「難易度の高いサンプル」でBefore/Afterを比較検証
# テストデータの定義(意図的に課題A, B, Cを誘発しやすい内容)
# A: 記事にない情報を幻覚しやすい(簡素な内容)
# B: 重要そうで実は無関係(スコアを間違えやすい)
# C: アクションが定まりにくい(抽象的なニュース)
problematic_sample = {
"title": "Acme Corpが社内ログ解析にAI導入を発表",
"news_content": "Acme Corpは本日、社内のサーバーログ解析に自社開発のAIツールを導入したと発表しました。これによりIT部門の障害対応時間が短縮される見込みです。製品としての外販予定については言及されていません。",
"user_context": "メディア・エンターテインメント業界でAIを活用したコンテンツ制作"
}
print("🔎 検証: 難易度の高いサンプルでの比較")
print("-" * 60)
print(f"タイトル: {problematic_sample['title']}")
print(f"文脈: {problematic_sample['user_context']}")
print("-" * 60)
# 最適化前 (Baseline)
print("\nBefore (Baseline):")
try:
res_base = writer_baseline(
title=problematic_sample['title'],
news_content=problematic_sample['news_content'],
user_context=problematic_sample['user_context']
)
print(f"Score: {res_base.impact_score}")
print(f"Action: {res_base.short_term_action}")
print(f"Summary: {res_base.article_summary}")
except Exception as e:
print(f"Error: {e}")
# 最適化後 (MIPRO)
print("\nAfter (MIPRO Optimized):")
try:
res_opt = mipro_optimized_writer(
title=problematic_sample['title'],
news_content=problematic_sample['news_content'],
user_context=problematic_sample['user_context']
)
print(f"Score: {res_opt.impact_score}")
print(f"Action: {res_opt.short_term_action}")
print(f"Summary: {res_opt.article_summary}")
except Exception as e:
print(f"Error: {e}")
print("-" * 60)🔎 検証: 難易度の高いサンプルでの比較
------------------------------------------------------------
タイトル: Acme Corpが社内ログ解析にAI導入を発表
文脈: メディア・エンターテインメント業界でAIを活用したコンテンツ制作
------------------------------------------------------------
Before (Baseline):
Score: 2
Action: When: 今週中に/Who: 制作基盤担当(情シス・SRE)+制作PM/What: 直近1〜3か月の障害ログを棚卸しし「頻出障害トップ5」と必要ログ項目(アクセス/エラー/ジョブ/配信)を定義、AI解析(既存AIOps/LLM要約でも可)の小規模PoC計画を作成/Where: 社内の監視基盤(例:SIEM/ログ管理)上で/Why: 障害対応時間短縮と制作停止リスク低減の効果を定量化するため/How: ①ログ収集範囲決定→②匿名化/権限設計→③アラート要約・原因候補提示の検証→④MTTR/検知時間で評価、の手順で2週間PoCを回す。
Summary: Acme Corpが社内サーバーログ解析に自社AIツールを導入。IT部門の障害対応時間短縮を見込むが、外販予定には触れず。AIによる運用高度化の社内活用事例。
After (MIPRO Optimized):
Score: 2
Action: Who: 情シス(SRE/インフラ)主導、制作システム担当(編集・配信)とセキュリティ/法務を巻き込み/What: 「制作に影響の大きい障害トップ10」と該当ログ種別(配信、ストレージ、レンダー、認証等)を棚卸しし、AIログ解析の適用可否(データ機微度・必要なマスキング・期待KPI)を決めるミニ調査+小規模PoC計画を作成/When: 半日で棚卸し、1週間でPoC計画確定/Where: 既存のログ基盤(SIEM/監視ツール/クラウドログ)上で/Why: 直接の制作AIではないが、基盤停止の損失を減らす施策として投資対効果を見極めるため/How: KPIをMTTR(復旧時間)、一次切り分け時間、誤検知率、重大障害の見逃し件数に設定し、機微情報のマスキング手順とアクセス権限(最小権限)を先に定義した上で、限定システムから段階導入する。
Summary: Acme Corpは社内のサーバーログ解析に自社開発AIツールを導入したと発表。IT部門の障害対応時間短縮が見込まれる。製品としての外販予定には触れていない。
------------------------------------------------------------上記の結果、Impact Score自体はどちらも「1」や「2」で変わらない場合でも、出力の品質に差異が生まれました。
MIPROは、単にスコアを合わせるだけでなく、「なぜそのスコアなのか」「次にどう動くべきか」という説明責任(Accountability)の能力を、プロンプトの自動書き換えによって向上させました。